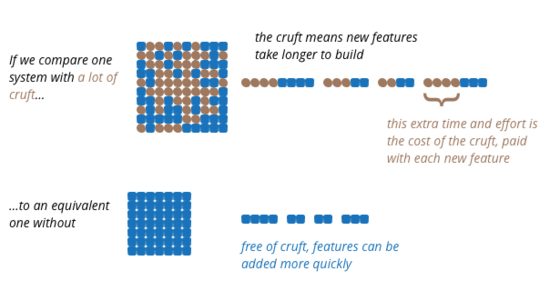
At this point we run into why this is a pseudo-graph. There is no way of measuring the functionality delivered by a software team. This inability to measure output, and thus productivity, makes it impossible to put solid numbers on the consequences of low internal quality (which is also difficult to measure). An inability to measure output is pretty common among professional work – how do we measure the productivity of lawyers or doctors?
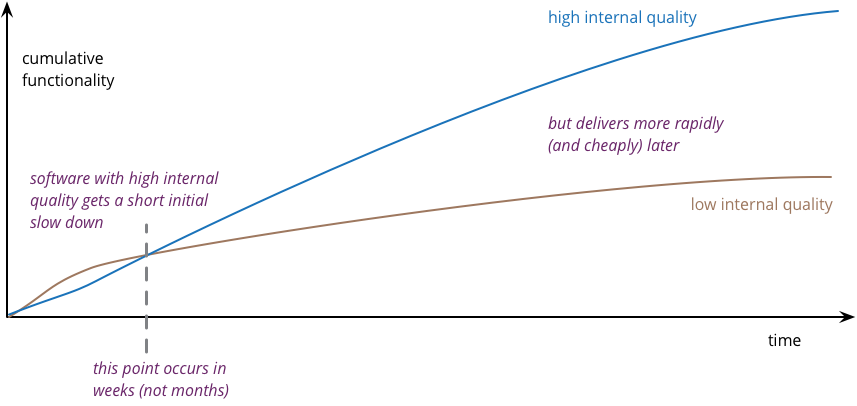
The way I assess where lines cross is by canvassing the opinion of skilled developers that I know. And the answer surprises a lot of folks. Developers find poor quality code significantly slows them down within a few weeks. So there’s not much runway where the trade-off between internal quality and cost applies. Even small software efforts benefit from attention to good software practices, certainly something I can attest from my experience.
As I mentioned above, we don’t really know how to measure internal quality, or productivity, and so it’s difficult to get quantifiable evidence for the importance of internal quality. However in recent years, there has been increasing efforts to try.
One particularly interesting paper that I’ve come across is this study from Adam Tornhill and Markus Borg. They use their proprietary tool, CodeScene, to determine the health level of files in 39 proprietary code bases. They found that resolving issues in low quality took more than twice as long as doing so in high quality code, and that low quality code had 15 times higher defect density.